
So far we’ve seen how the code we write is composed of smaller parts, like expressions and statements. But how many statements and/or expressions are needed to consider it an algorithm? At what point does a set of algorithms become what we call frameworks? And when does a framework differ from a utility or a library?
If we wanted to explain it practically, we could think of atomic design where expressions generate statements, statements generate algorithms and these finally become code.
- Expressions are the minimum unit with functional meaning.
- Statements are composed of one or more expressions.
- Algorithms are a set of multiple statements and expressions.
- Code is one or several algorithms focused on solving a product or business need.
💧 Algorithm and code are sometimes used as synonyms. However, colloquially, we often call a specific part of a product an algorithm. We might hear things like “the search algorithm” or “the discount algorithm”, etc.
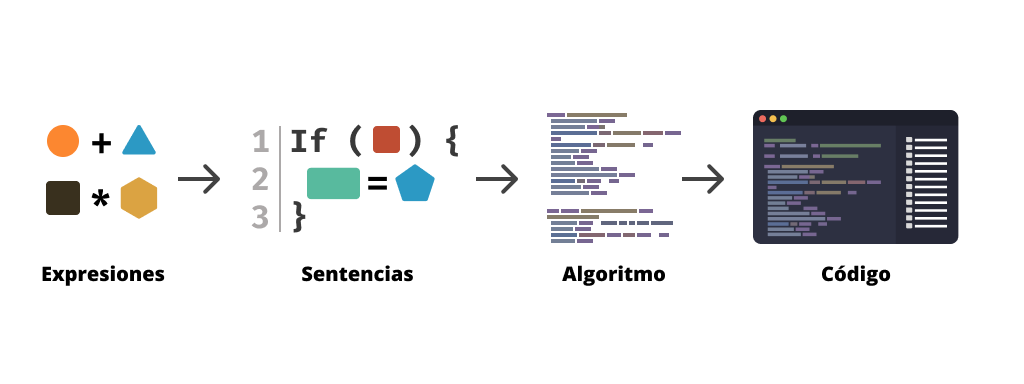 Expressions are the smallest units, which compose themselves to generate code.
Expressions are the smallest units, which compose themselves to generate code.
Code can be many things
When we talk about code, we can be referring to many things, similar to what happens with the word algorithm. However, certain pieces of code can be categorized according to their function and size and yet, they all continue to be considered “code”.
- Utilities: small and specific pieces of code that solve a concrete task.
- Libraries: sets of utilities grouped with a common purpose.
- Frameworks: larger libraries that include multiple utilities and add structure, rules or conventions for developing a product.
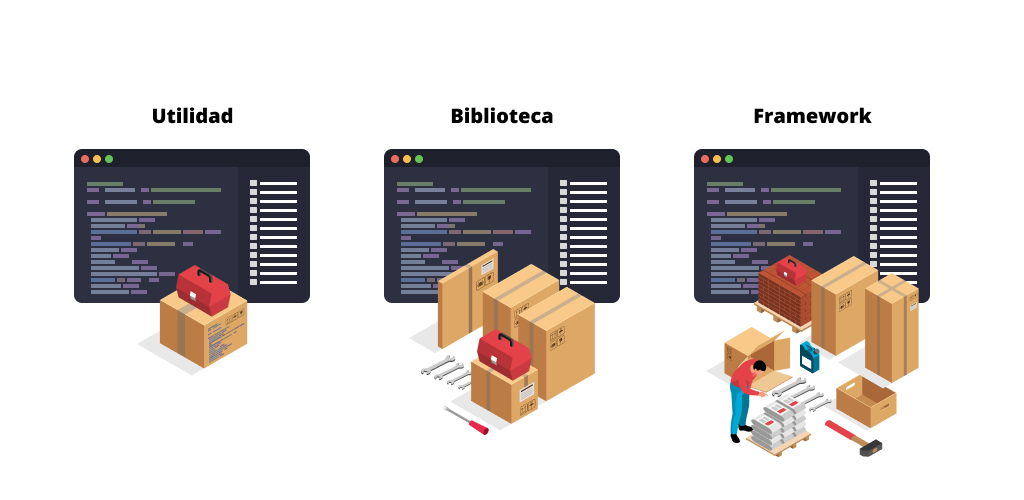 Utilities, libraries and frameworks can be seen as different types within the code ecosystem: from the simplest to the most sophisticated.
Utilities, libraries and frameworks can be seen as different types within the code ecosystem: from the simplest to the most sophisticated.
Algorithms in code
An algorithm is not always something complex or mysterious. We often use it without realizing it, because it’s nothing more than a sequence of steps to solve a specific problem, as we’ve discussed before. In a project, we usually hear phrases like “the search algorithm” or “the algorithm that calculates discounts”. In those cases, we’re talking about concrete fragments within a larger system.
However, algorithms by themselves are not a finished product. And, in a business context, when talking about “algorithm” they often don’t refer to a specific piece of code, but to a broader concept that can encompass multiple algorithms or even an entire codebase.
A very common example is the “social media algorithm” that decides what we see. In practice it’s not a single algorithm as we’ve defined it here: a sequence of statements and expressions, but a huge set of algorithms, repositories and systems. But it’s called an “algorithm” because it sounds attractive, automated, almost magical. It works as marketing, conveys the idea of objectivity and neutrality, even though behind it there are human decisions and much more complex rules.
In short, at a technical level, an algorithm remains what we described here. We just need to keep in mind that, outside the strictly technical field, the word is often used to describe a “magical” characteristic of a product.
Utilities and Helpers
When we start organizing our pieces of code a bit, a very common category appears: utilities.
Utilities are usually small functions that don’t dictate how the application should work, but help solve very specific tasks, generally repetitive ones.
A classic example is formatting. Imagine we need to transform a number into a currency format, for example from 2333.4 to $2,333.40, or that we receive a date in ISO 8601 standard, for example 2025-10-12T22:27:06.416Z and we want to display it as Sunday, Oct 13, 12:27 AM or even in a more human way like 32 minutes ago.
Formatting utilities are just one type. There are also utilities for manipulating objects, arrays, text strings, events and much more.
What’s interesting about utilities is that, by solving common problems, they can be used in practically any project. However, there are other functions that, although they fulfill a similar role, depend too much on business logic or the particular context of a project. Those are usually called helpers.
Having a clear distinction between utilities and helpers makes it easier to reuse code in future projects. Utilities can almost always be moved from one place to another without problems, while helpers have more limitations because they depend on a specific use case. Still, if a project shares similar goals or characteristics, a helper can also be reused.
Some common examples of helpers are:
- Email template formatting: the content is usually very particular for each product.
- Dynamic URL generation: joining routes and parameters to build links within a web application.
In both cases they fulfill the same idea: they help, but only within their own context.
Libraries
Another category that usually classifies the type of code is when a series of utilities oriented to a common purpose accumulate. This collection is called a library, and its main idea is that it’s ready to be distributed and used in any project.
Libraries are usually born when a set of solutions begins to repeat over and over again: functions to handle dates, make HTTP requests or manipulate interfaces. Instead of rewriting them in each project, they are grouped, documented and shared to facilitate their reuse.
In addition to saving time, libraries provide consistency: they allow solving the same problems uniformly, without depending on how each person implements them. So, creating a library involves thinking about something more than code: you have to design a clear interface, maintain versions and document its use so others can understand and adopt it easily.
The important thing is that a library is at the service of the developer, it doesn’t impose rules or structure. We are the ones who decide how and when to use it. However, when a library grows too much and starts to define conventions or work patterns, it stops being just a collection of utilities to become something bigger: a framework.
Frameworks
Although I would like to say that the pattern repeats and that a framework is simply a set of libraries, the truth is that it goes much further than that.
It’s inevitable that a framework includes its own utilities, helpers and, in many cases, multiple libraries. However, what really differentiates it from other pieces of code is its purpose. A framework has a series of built-in opinions and decisions about how things should be done, with the purpose that we don’t have to devise a solution from scratch for each common problem.
While a library is at our service, in a framework the opposite happens: we work within its structure. The framework is the one who decides when and how our code is executed.
We could classify frameworks into three large groups:
- Conventional frameworks: they focus on solving a specific area of development, such as backend, interface or communication between components. They are flexible and allow us to decide which other tools to combine them with.
- Full-stack frameworks: they cover the entire application construction process. They define how the project is organized and usually include everything from the database structure to the server code and user interface. They require less manual intervention and are almost ready to use for the purpose they were created for, such as an e-commerce or a content management system.
- Metaframeworks: they are built on top of other existing frameworks and offer an additional level of integration and scalability. They don’t dictate exactly how to do each thing, but they do include tools and conventions to facilitate development, optimize performance and scale complex applications.
In any case, all frameworks share a common idea: they seek to accelerate development and offer coherence. They free us from repetitive decisions, although in return they ask us to accept their rules.
Let’s not forget the most important thing: The product
In software development, in addition to the classifications we’ve already seen, there are many other concepts such as patterns, paradigms, design strategies and ways to build more effective solutions. Some approaches are more opinionated, they tell us how we should do things and others are more free, allowing us to decide how to use the tools.
In the end, choosing which framework, utility or library to use is usually a matter of personal preference or community adaptation. The frameworks and libraries that endure are not always the technically best ones, but those that manage to be easily adopted, have good documentation, or have behind them a community or company that gives them constant support. Sometimes they become popular because they are innovative; others, simply because they arrived at the right time.
But none of that guarantees the success of a product. Using the “best” framework or the most modern library doesn’t ensure that what you build will have impact. What’s truly important, and what we must not forget, is the final purpose: the product, service or idea we’re creating.
Users don’t care if you used the latest library, the trendy language or a low-code tool. The only thing that really matters is that the product works and solves their need.
So, when you choose a framework or library, don’t worry so much about which one is “the best”. Check if it aligns with your purpose, if it has an active community and good documentation. And if you simply like it, that’s fine too. The important thing is that it allows you to build something that motivates you and adds value.
Finally, remember that it’s also valid not to use frameworks or libraries and create your own when you need them. Just make sure it doesn’t become paradoxical: spending more time building tools than developing the product you actually needed them for.



